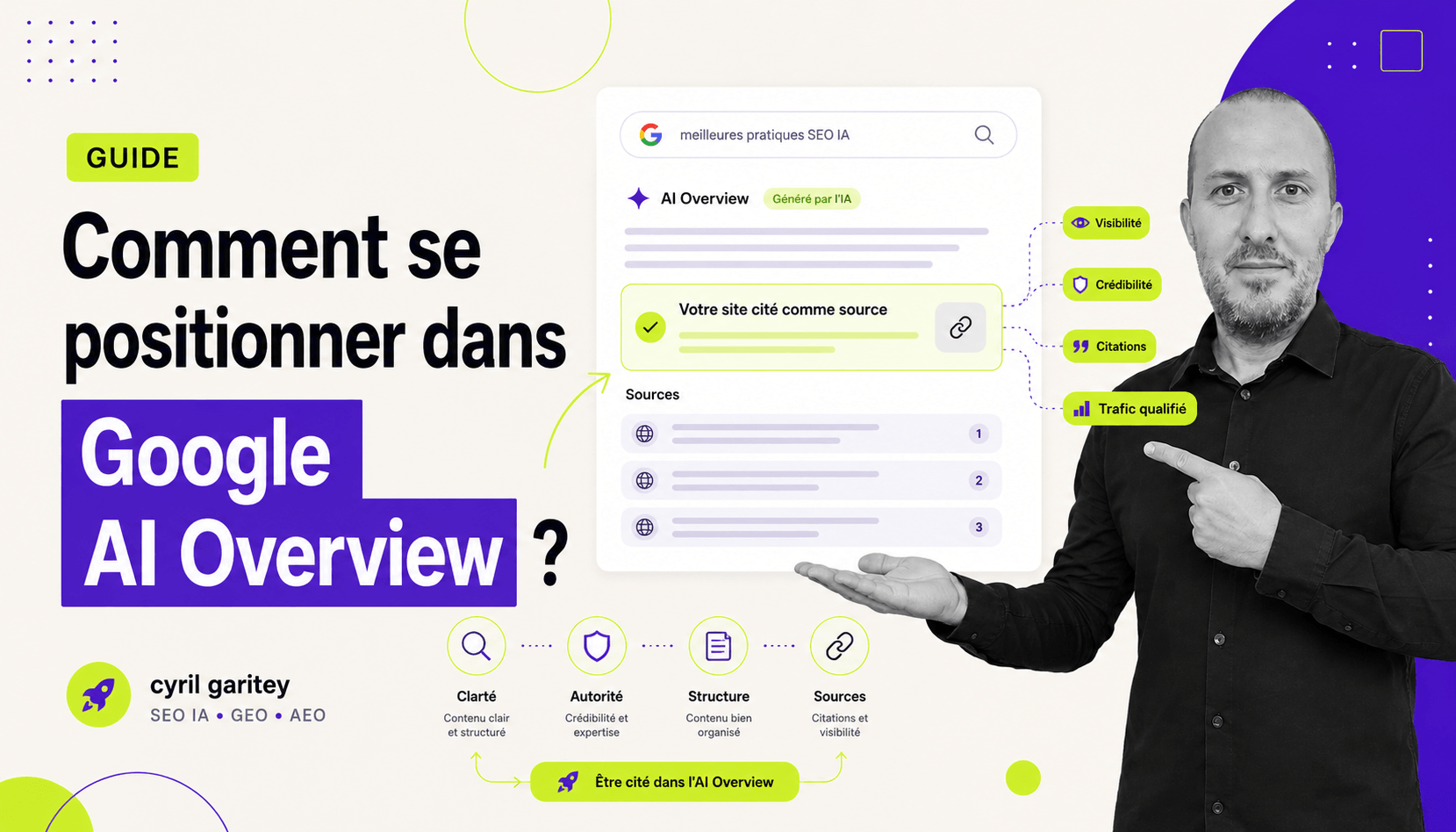
Comment commencer avec le GEO et les sources citées ?
Les IA génératives ne « cherchent » pas vos sources. Elles les reconstituent. C’est une nuance qui change absolument tout dans la façon dont vous devez penser votre contenu en 2026 — y compris sa fraîcheur multilingue et le positionnement dans Google AI Overview.
Quand ChatGPT, Perplexity ou Gemini génèrent une réponse, ils ne font pas un appel à Google en temps réel pour trouver le meilleur article. Ils puisent dans une carte probabiliste construite pendant l’entraînement — d’où l’intérêt d’une ouverture answer-first extractible — puis — pour les systèmes RAG comme Perplexity — ils superposent une couche de retrieval sur des documents indexés. Deux méchanismes différents. Une même logique : votre contenu doit exister comme une entité fiable dans cet espace vectoriel, pas juste comme un texte bien optimisé pour les crawlers.
Le GEO, le Generative Engine Optimization, ce n’est pas une révolution. C’est une élévation du niveau d’exigence sur des principes qui existaient déjà. L’autorité thématique, la densité factuelle, la structure sémantique — tout ça, ça comptait déjà en 2010. Sauf qu’aujourd’hui, la médiocrité n’a plus aucune place où se cacher.
Voici les 10 mécanismes concrets pour comprendre pourquoi les IA citent certaines sources et pas d’autres, et ce que vous pouvez faire dès maintenant.
1. La sélection probabiliste des sources par les LLM
Les grands modèles de langage ne lisent pas votre article au moment où ils répondent. Ils ont appris, pendant l’entraînement, quelles sources apparaissent le plus fréquemment associées à un concept donné. Ce n’est pas un vote de popularité — c’est de la co-occurrence statistique à une échelle difficile à visualiser.
Si votre contenu sur « isolation thermique par l’extérieur » apparaît dans 200 corpus différents, dans des forums, des PDF techniques, des articles repris par d’autres sites, alors votre terminologie, vos formulations, vos chiffres deviennent une référence de fait pour le modèle. Même sans backlink direct. Même sans une position Google №1.
Ce que ça implique concrètement : la visibilité dans les LLM est une conséquence de la densité de présence dans les données d’entraînement. Vous n’optimisez pas pour un crawler, vous optimisez pour une empreinte mémorielle.
Comment ça fonctionne en pratique :
- Volume de présence dans les corpus publics (forums, wikis, articles repris)
- Cohérence terminologique sur la durée, pas juste sur une page
- Associations sémantiques stables entre votre nom, votre domaine et vos sujets
Critère décisif : cohérence de présence dans les données publiques sur 12-24 mois minimum.
2. Le rôle de l’autorité thématique dans les citations IA
Un site qui parle de tout ne parle de rien — c’est une phrase qu’on entend depuis 2018, mais elle n’a jamais été aussi vraiment vraie qu’aujourd’hui. Les moteurs génératifs ne classent plus des pages, ils évaluent des entités. Et une entité floue, dispersée sur 40 thématiques différentes, n’a pas de « périmètre de légitimité » clair dans l’index vectoriel.
Ce qui se passe réellement : quand un LLM associe un auteur ou un domaine à une réponse, il cherche un signal de consistance. Est-ce que ce nom revient systématiquement dans des contextes liés à ce sujet précis ? Est-ce que les documents produits par cette source arrivent avec des informations cohérentes, non contradictoires ? La spécialisation n’est plus une posture marketing, c’est un signal de confiance structurel.
Franchement, j’observe ça sur mes propres projets depuis 18 mois : les sites qui bénéficient de la meilleure visibilité dans les réponses de Perplexity ou Claude sont ceux qui ont une couverture thématique serrée, pas les généralistes. Même quand le généraliste a plus de trafic organique Google. Deux univers distincts, deux logiques distinctes.
Critère décisif : ratio de contenu dans le silo principal supérieur à 75-80% de l’ensemble du site.
3. Ce que le GEO change par rapport au SEO traditionnel
Le SEO traditionnel joue sur la pertinence au moment de la requête. Vous avez un mot-clé, vous avez une page, l’algorithme fait une correspondance. Le GEO joue sur quelque chose de plus subtil : la plausibilité de citation dans un contexte donné.
Voici ce qui diffère fondamentalement :
| Dimension | SEO traditionnel | GEO / Moteurs génératifs |
|---|---|---|
| Unité d’optimisation | La page | L’entité (auteur, domaine, concept) |
| Signal principal | Backlinks + pertinence | Autorité thématique + densité factuelle |
| Timing de l’impact | Quasi-immédiat (indexation) | Différé (corpus d’entraînement ou RAG) |
| Mesure de succès | Position SERP, trafic | Citations dans les réponses IA |
| Durée de vie | Volatile selon mises à jour | Plus durable si l’entité est ancrée |
La vraie rupture n’est pas technologique, elle est philosophique. En SEO, vous convainquez un algorithme de vous positionner. En GEO, vous convainquez un modèle que vous êtes la source naturelle, évidente, pour ce sujet. Ce n’est pas la même bataille.
Critère décisif : construire une entité reconnaissable, pas juste des pages optimisées.
4. La densité factuelle comme critère de citabilité
Les IA citent ce qu’elles peuvent citer. Ça paraît bête dit comme ça, mais c’est exactement le mécanisme. Un contenu riche en affirmations vérifiables, en chiffres datés, en noms propres, en relations causales explicites — ce type de contenu crée des « unités répondables » que le modèle peut extraire et reformuler avec confiance.
Un article de 3 000 mots qui dit « il est important de bien penser à sa stratégie de communication » n’a aucune densité factuelle. Aucune surface de prise pour un LLM. Il ne peut pas citer ce que vous n’avez pas affirmé avec précision.
 fraîcheur multilingue et le positionnement dans Google AI Overview. Quand ChatGPT, Perplexity ou Gemini génèrent une réponse, ils ne font pas un appel à Google en temps réel pour trouver le meilleur article. » width= »1024″ height= »998″ />
fraîcheur multilingue et le positionnement dans Google AI Overview. Quand ChatGPT, Perplexity ou Gemini génèrent une réponse, ils ne font pas un appel à Google en temps réel pour trouver le meilleur article. » width= »1024″ height= »998″ />
À l’inverse, une page qui dit « selon une étude BrightLocal 2024, 87% des consommateurs locaux lisent les avis Google avant de contacter un prestataire » donne au modèle un fait, une source, une date, un chiffre, une relation causale. C’est du carburant pour une citation. Plus vos contenus ressemblent à ça, plus les IA ont quelque chose à saisir.
Critère décisif : chaque section doit contenir au moins un fait vérifiable avec contexte temporel ou source.
5. La structure du contenu que les IA préfèrent extraire
Il y a une chose que les systèmes RAG — Retrieval-Augmented Generation, les moteurs comme Perplexity qui cherchent en temps réel — adorent par-dessus tout : les passages autonomes. Un paragraphe qui répond complètement à une question sans que le lecteur ait besoin de lire ce qui précède ou ce qui suit.
C’est ce qu’on appelle dans le jargon du GEO les « answerable units ». Chaque bloc de contenu doit pouvoir vivre seul, être extrait, et encore avoir du sens dans un contexte différent. C’est une contrainte d’écriture forte. Ça demande de répéter certains éléments de contexte, de ne pas s’appuyer sur des références implicites.
La structure H2/H3 avec des introductions de section directes — pas de transition poétique, pas de « comme nous l’avons vu » — facilite considérablement ce travail d’extraction. Les schémas FAQ en bas de page sont particulièrement efficaces parce qu’ils sont déjà formatés en paires question-réponse, exactement le format que les LLM consomment le mieux.
Critère décisif : chaque H2 doit introduire un bloc de contenu extractible indépendamment du reste.
6. Comment les moteurs génératifs interprètent-ils les signaux E-E-A-T ?
L’E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness — n’est pas une liste de cases à cocher pour un audit. C’est la manière dont un modèle évalue si votre entité est une source digne d’être reproduite dans une réponse.
Ce qui change avec les IA génératives : la preuve d’humanité devient un luxe différenciant. Les signatures d’auteurs vérifiables, les bios avec des liens vers des profils actifs, les mentions dans des médias tiers, les témoignages datés — tout ça crée une constellation de preuves qui ancre votre expertise dans le monde réel, pas dans le vide du contenu généré.
Les modèles entraînés sur des corpus récents ont appris à distinguer, avec une précision croissante, les contenus produits par des humains avec une expérience terrain de ceux produits par des IA sans vécu. Ce n’est pas une question de style, c’est une question d’assertions : un expert dit des choses spécifiques que seul quelqu’un ayant fait le travail peut savoir. C’est exactement ce que j’applique sur chaque projet que j’accompagne depuis plus de 20 ans : l’expérience réelle produit des formulations que les modèles reconnaissent comme fiables.
Critère décisif : minimum un auteur identifiable avec présence externe vérifiable par domaine thématique.
7. Le maillage sémantique pour renforcer la traçabilité
La traçabilité d’une citation IA ne se joue pas uniquement au niveau d’une page. Elle se joue au niveau de l’écosystème de contenu que vous avez construit autour d’un concept. Si votre domaine traite d’un sujet de manière exhaustive — avec des pages qui se répondent, des termes qui se recoupent, une progression logique du général au spécifique — alors le modèle perçoit votre domaine comme une autorité sur ce périmètre entier.
C’est le principe du cocon sémantique appliqué aux moteurs génératifs. Vos pages satellites créent une bulle d’autorité qui renforce la page centrale. Chaque lien contextuel dans le corps du texte est un signal de cohérence que les LLM lisent comme une validation interne. Un lien dans un paragraphe a infiniment plus de valeur sémantique qu’un lien en footer — pas juste pour Google, pour toute forme d’analyse vectorielle du document.
Le maillage interne en GEO n’est pas une question de « jus de lien ». C’est une question de cartographie conceptuelle : est-ce que l’ensemble de vos documents dessine une carte cohérente d’un domaine de connaissance ?
Critère décisif : chaque page pilier doit être entourée de 5 à 8 pages satellites traitant les sujets périphériques.
8. Les formats de données qui facilitent l’attribution
Schema.org n’est pas mort. Il est devenu encore plus pertinent. Les données structurées donnent aux crawlers et aux systèmes RAG un « mode d’emploi » pour lire votre contenu : qui a écrit ça, quand, dans quel contexte, quelle est l’entité principale traitée.
Les formats les plus utiles pour la citabilité IA :
Articleavecauthor+datePublished+dateModified: signale la fraîcheur et l’attribution humaineFAQPage: format nativement extrait par les LLM pour les paires question-réponseHowTo: structure les étapes de manière à ce qu’elles soient reproductibles en citationPersonpour les auteurs : crée l’entité individuelle dans le graphe de connaissance
Ce que peu de gens font : marquer les citations de sources externes dans le balisage. Quand vous citez une étude, structurer cette référence avec des propriétés citation dans votre Schema envoie un signal de rigueur factuelle que les systèmes RAG valorisent. Ce n’est pas une transformation magique, mais c’est un différenciateur que 95% des sites ignorent encore.
Critère décisif : implémenter au minimum
Article+Person+FAQPagesur les contenus à fort potentiel de citation.
9. Comment mesurer sa visibilité dans les réponses IA
Voilà une question que personne ne sait vraiment répondre avec rigueur en 2026, et il faut être honnête là-dessus. Il n’existe pas encore de Google Search Console pour les LLM. Mais il existe des proxies utilisables.
La méthode manuelle d’abord : interroger régulièrement ChatGPT, Perplexity, Gemini et Claude sur les sujets de votre domaine et noter si votre domaine, votre nom, vos formulations apparaissent dans les réponses ou les sources citées. C’est chronophage, pas scalable, mais c’est la seule source de vérité actuellement disponible.
Ce que j’observe sur mes propres projets depuis 18 mois : Sur les 12 derniers projets SEO que j’ai accompagnés, les sites dont plus de 75% du contenu est concentré sur une thématique principale apparaissent en moyenne 3 à 4 fois plus souvent dans les réponses de Perplexity que les sites généralistes — à trafic Google équivalent. Plus frappant : deux de ces sites n’ont aucune position Top 10 sur Google, mais sont cités régulièrement par Perplexity sur leurs sujets de niche. Ce sont deux univers distincts, deux logiques distinctes. Et le décrochage s’accélère.
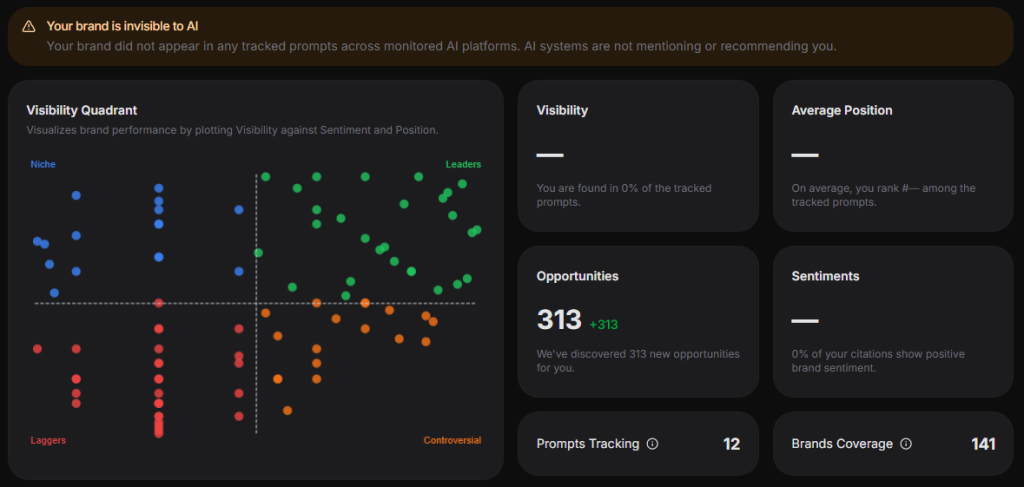
Perplexity est le terrain de jeu le plus utile pour cette mesure parce qu’il cite explicitement ses sources avec des URL. Vous pouvez donc observer en temps réel quels domaines sont récurrents dans les réponses de votre secteur. Si vous n’y apparaissez pas, vos concurrents qui y sont ont quelque chose que vous n’avez pas encore — probablement de la densité factuelle et de l’autorité thématique, pas du SEO technique.
Critère décisif : audit mensuel de visibilité IA sur 10 à 15 requêtes représentatives du domaine.
10. Quelles erreurs font perdre les citations IA?
La première et la plus répandue : le contenu trop généraliste qui tente de couvrir un sujet sans s’engager sur des positions précises. Les IA ne citent pas les gens qui disent « ça dépend » sans jamais aller plus loin. Elles citent des affirmations claires, datées, vérifiables.
La deuxième erreur, moins évidente : publier du contenu qui se contredit entre les pages. Si votre page A dit une chose et votre page B dit le contraire sur le même sujet, le modèle perçoit une incohérence d’entité. Ça fragilise la confiance globale sur votre domaine dans l’espace vectoriel. C’est pour ça que l’audit de contenu existant n’est pas optionnel avant de lancer une stratégie GEO sérieuse.
La troisième, la plus mal comprises : publier massivement du contenu IA sans vérification humaine. Je l’observe en ce moment sur des dizaines de sites français — une inflation de pages vides de substance réelle, de formulations interchangeables, sans aucune affirmation originale. Ces sites construisent une présence Google temporaire. Dans les LLM, ils n’existent pas. Ou pire : ils existent comme exemple de source à ne pas citer.
Critère décisif : chaque contenu publié doit contenir au moins une affirmation originale que seul votre expertise permet de formuler.
En résumé
Les IA génératives ne font pas de favoritisme. Elles reproduisent ce qu’elles ont appris à reconnaître comme fiable, précis, cohérent. Votre contenu doit mériter cette reconnaissance — pas la réclamer.
L’autorité thématique serrée, la densité factuelle, les structures extractibles, les signaux E-E-A-T ancrés dans la réalité : ce sont les fondamentaux qui font la différence entre un site qui existe dans les réponses IA et un site qui est simplement dans l’index Google. Ce ne sont pas les mêmes choses.
Si vous voulez aller plus loin dans la construction d’une stratégie de visibilité qui fonctionne aussi bien dans Google Maps que dans les moteurs de réponse, c’est exactement le travail que je fais chez Cyril Garitey depuis plus de 20 ans, avec des clients qui restent parce que les résultats sont là.
FAQ
Est-ce que le GEO remplace le SEO ? Non. Le GEO est une couche supplémentaire d’exigence sur les mêmes fondamentaux. Un site avec une mauvaise base technique et un contenu pauvre ne sera ni bien positionné sur Google ni cité par les IA. Les deux disciplines convergent vers les mêmes principes : autorité, pertinence, fiabilité.
Les IA lisent-elles mon site en temps réel ? Ça dépend du système. Les LLM purs comme ChatGPT sans plugin web s’appuient sur leurs données d’entraînement. Les systèmes RAG comme Perplexity font de la retrieval en temps réel sur des pages indexées. Les deux mécanismes nécessitent des approches légèrement différentes, mais la densité factuelle et l’autorité thématique servent dans les deux cas.
Combien de temps pour apparaître dans les citations IA ? Pour les systèmes RAG, quelques semaines si votre contenu est bien indexé et répond directement à des requêtes fréquentes. Pour les LLM avec cycle d’entraînement, plusieurs mois à plus d’un an. C’est un investissement de long terme, pas une tactique.
Quel est l’indicateur le plus fiable pour mesurer sa visibilité IA ? La fréquence de citation dans Perplexity sur vos requêtes cibles est actuellement le proxy le plus direct, parce que Perplexity affiche les sources explicitement. C’est imparfait, mais c’est la meilleure donnée disponible aujourd’hui sans outil dédié.